| Common Table Expressions (CTE) | CTE: WITH ordersWith100OrMoreAmount AS ( SELECT customer_name, order_date FROM orders WHERE order_amount > 100 ) SELECT * FROM ordersWith100OrMoreAmount; CTE With Recursion: Returns list of all the employee ids who are managers of one or more employees: WITH managers ( employee_id, manager_id, emp_level ) AS ( SELECT employee_id, manager_id, 1 FROM employees WHERE manager_id IS NULL UNION ALL SELECT e.employee_id, e.manager_id, m.emp_level + 1 FROM employees e JOIN managers m ON m.employee_id = e.manager_id) SELECT distinct manager_id FROM managers; |
| Connect By | Returns list of all the employee ids who are managers of one or more employees (Results are similar to CTE with Recursion query mentioned above): SELECT DISTINCT manager_id FROM employees START WITH manager_id IS NULL CONNECT BY PRIOR employee_id = manager_id; |
| Window Functions | Aggregate Functions: AVG() – Select department, avg(salary) from employees group by department; (– It gives an aggregate result, not row level) VS. Select empId, department, salary, avg(salary) over (partition by department ) as dept_avg from employees; (– It gives a row level result) BIT_AND() BIT_OR() BIT_XOR() COUNT() JSON_ARRAYAGG() JSON_OBJECTAGG() MAX() MIN() STDDEV_POP(), STDDEV(), STD() STDDEV_SAMP() SUM() VAR_POP(), VARIANCE() VAR_SAMP() Non-Aggregate Functions: CUME_DIST() DENSE_RANK() FIRST_VALUE() LAG() LAST_VALUE() LEAD() NTH_VALUE() NTILE() PERCENT_RANK() RANK() ROW_NUMBER() SELECT e.employee_id, e.first_name, d.department_name, e.salary, round(avg(e.salary) over(), 2) as overall_avg_sal, round(avg(e.salary) over (partition by d.department_id),2) as dept_avg_sal, round(min(e.salary) over (partition by d.department_id),2) as dept_min_sal, round(max(e.salary) over (partition by d.department_id),2) as dept_max_sal, rank() over (order by e.salary desc) as overall_rank, rank() over(partition by d.department_id order by e.salary desc) as dept_rank, dense_rank() over (partition by d.department_id order by e.salary desc) as dept_dense_rank, round(cume_dist() over (partition by d.department_id order by e.salary desc),2) as dept_cume_dist, first_value(e.salary) over (partition by d.department_id order by e.salary desc) as dept_first_val, last_value(e.salary) over (partition by d.department_id order by e.salary desc) as dept_last_val, nth_value(e.salary,2) over (partition by d.department_id order by e.salary desc) as dept_nth_val, ntile(4) over (partition by d.department_id order by e.salary desc) as dept_ntile_val, lag(e.salary,1,0) over (partition by d.department_id order by e.salary desc) as lag, lead(e.salary,1,0) over (partition by d.department_id order by e.salary desc) as lead, round(PERCENT_RANK() over (partition by d.department_id order by e.salary desc),2) as percent_rank FROM employees e JOIN departments d ON d.department_id = e.department_id order by d.department_id; 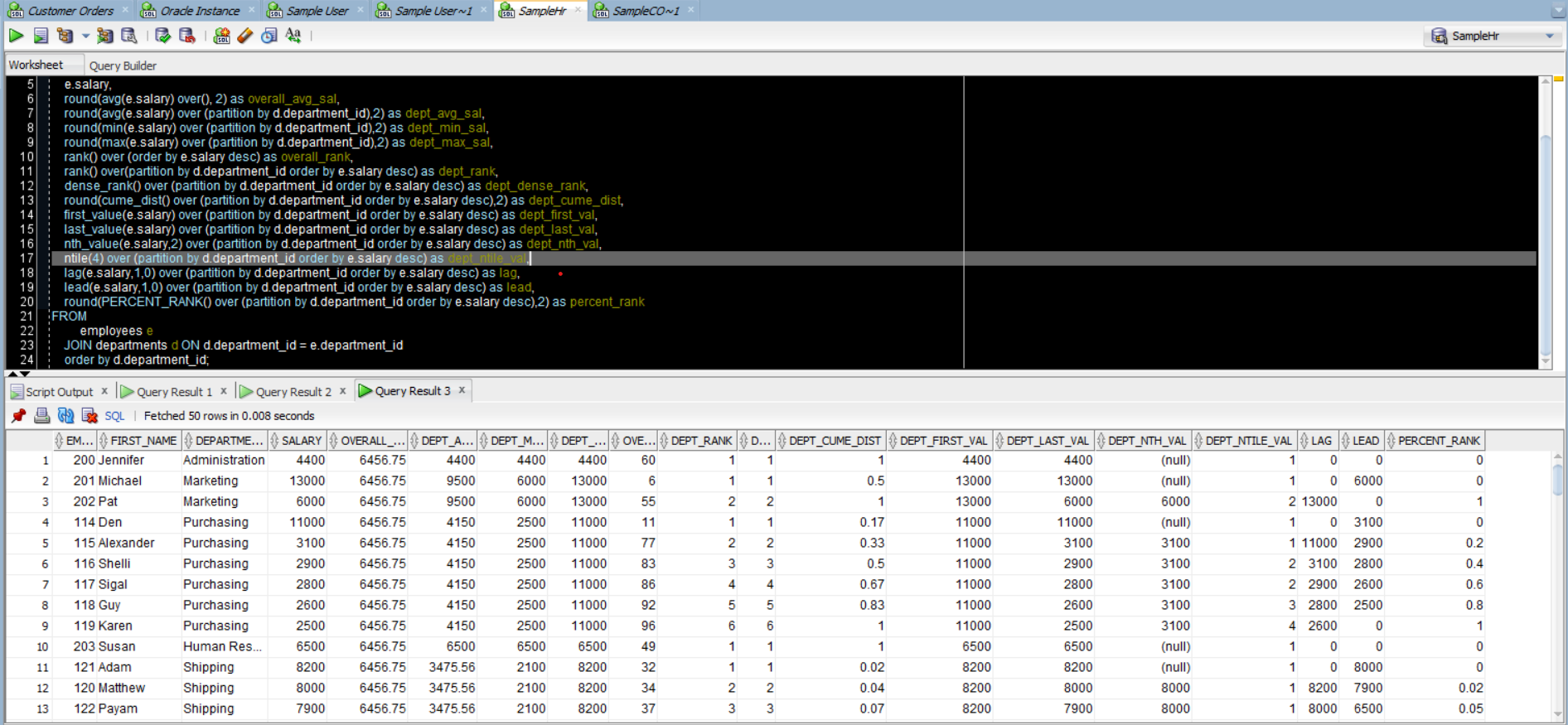 |
| Pivot | select * from (SELECT d.department_name, e.salary FROM employees e JOIN departments d ON d.department_id = e.department_id) pivot( sum(salary) for department_name in (‘Marketing’, ‘Purchasing’) ); Output: 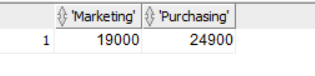 |